Cohen's Kappa Calculator
Calculate Cohen's kappa online from Excel or CSV ratings. Measure inter-rater agreement for categorical labels with AI.
Or try with a sample dataset:
Preview
What Is Cohen's Kappa?
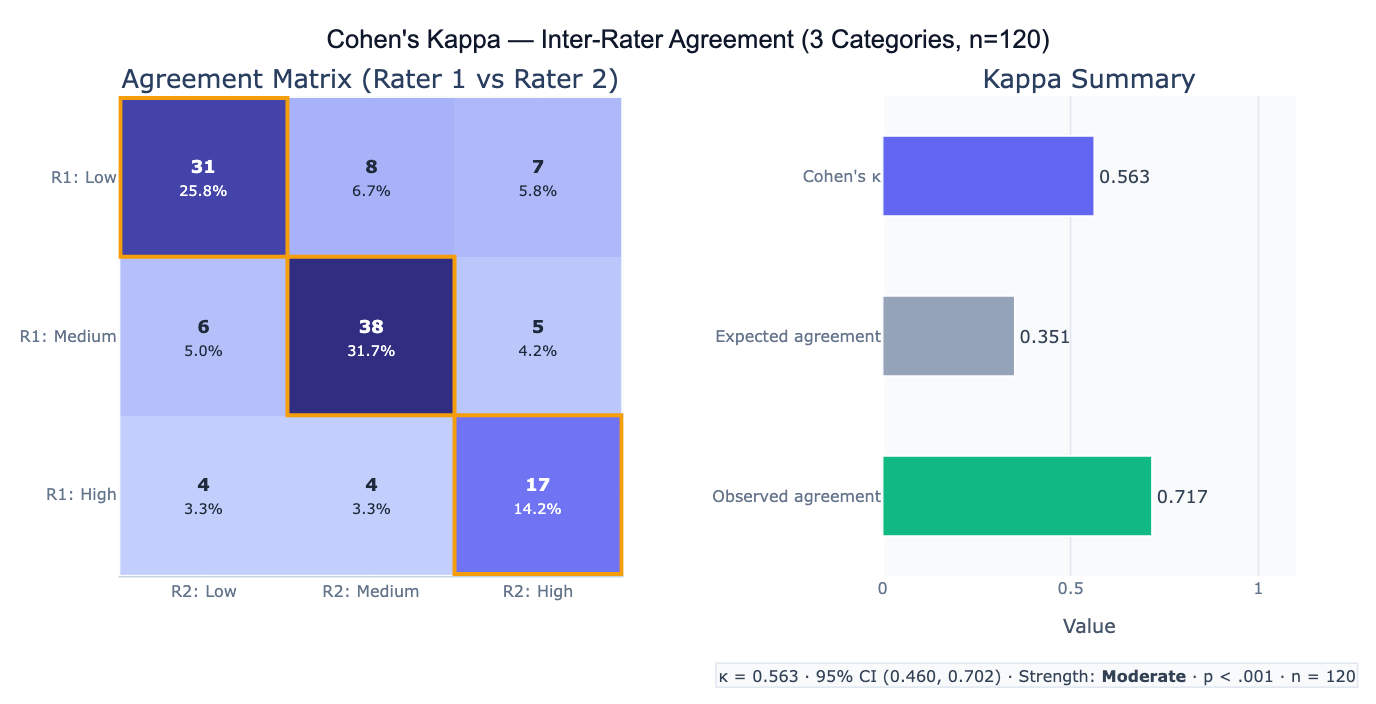
Cohen's kappa (κ) is the standard measure of inter-rater agreement for categorical data — it quantifies how consistently two raters (judges, coders, classifiers) assign the same categories to the same subjects, corrected for the agreement expected by chance. Simple percent agreement is misleading because two raters randomly assigning categories will agree by chance at a rate proportional to category prevalences — if both raters assign "positive" 90% of the time, they agree 81% of the time by chance even with zero skill. Kappa corrects for this: κ = (p_o − p_e) / (1 − p_e), where p_o is the observed agreement and p_e is the expected chance agreement. κ = 0 means agreement no better than chance; κ = 1 means perfect agreement; negative κ means agreement worse than chance (systematic disagreement).
The formula for chance-expected agreement is p_e = Σ (row_marginal_i × col_marginal_i), where the marginals represent each rater's category usage frequencies. For a binary classification (disease/no disease), if Rater 1 calls 70% positive and Rater 2 calls 65% positive, the expected chance agreement is 0.70×0.65 + 0.30×0.35 = 0.455 + 0.105 = 0.56 — so even perfect chance-level raters would agree 56% of the time. Weighted kappa extends the basic formula to ordinal categories, where partial credit is given for near-misses: a disagreement of one step (Low vs Medium) is penalized less than a large disagreement (Low vs High). Linear and quadratic weighting schemes are available; quadratic weighting (which penalizes large disagreements more heavily) is most common and equals the ICC(3,1) consistency for ordinal data.
A practical example: two radiologists classify 200 chest X-rays as Normal, Suspicious, or Malignant. Observed agreement = 74%, but expected chance agreement = 46%, yielding κ = (0.74 − 0.46) / (1 − 0.46) = 0.52 (moderate agreement). The agreement matrix reveals that most disagreements are between Suspicious and Malignant — both raters agree well on Normal cases (per-category κ = 0.81) but struggle to distinguish the two abnormal categories (per-category κ = 0.45 and 0.41). This directs training efforts: the raters need calibration on the Suspicious-to-Malignant boundary, not on identifying normal scans.
How It Works
- Upload your data — provide a CSV or Excel file with one column per rater, one row per subject. Each cell should contain the category label (text or numeric code) assigned by that rater.
- Describe the analysis — e.g. "2 raters, 3 categories (low/medium/high); compute Cohen's kappa with 95% CI; agreement matrix heatmap; per-category kappa; Landis & Koch interpretation"
- Get full results — the AI writes Python code using scikit-learn and Plotly to compute kappa, weighted kappa, 95% CI, per-category kappa, the full agreement matrix, and produce the heatmap visualization
Required Data Format
| Column | Description | Example |
|---|---|---|
rater1 | Categories assigned by rater 1 | low, medium, high (or 1, 2, 3) |
rater2 | Categories assigned by rater 2 | Same category labels as rater 1 |
subject | Optional: subject identifier | P001, case_12 |
Any column names work — describe them in your prompt. Both rater columns must use the same category labels. For Fleiss' kappa (3+ raters), provide one column per rater. Missing values (subject not rated by one rater) should be handled by excluding that subject or using pairwise deletion.
Interpreting the Results
| Output | What it means |
|---|---|
| κ (kappa) | Agreement corrected for chance — ranges from < 0 (worse than chance) to 1 (perfect) |
| 95% CI | Uncertainty in kappa — always report; wide CI with small n |
| Strength classification | Landis & Koch (1977): < 0.20 slight; 0.21–0.40 fair; 0.41–0.60 moderate; 0.61–0.80 substantial; > 0.80 almost perfect |
| Observed agreement (p_o) | Raw % agreement — misleading without chance correction |
| Expected agreement (p_e) | Chance agreement based on marginal category frequencies |
| Weighted kappa | Kappa giving partial credit for near-miss disagreements — appropriate for ordinal categories |
| Per-category kappa | Kappa treating each category as a binary (this category vs all others) — identifies which categories are hardest to agree on |
| Agreement matrix | Cross-tabulation of rater 1 vs rater 2 ratings — diagonal cells are agreements; off-diagonal are disagreements |
Example Prompts
| Scenario | What to type |
|---|---|
| Basic 2-rater kappa | 2 raters, columns rater1 and rater2; compute Cohen's kappa, 95% CI; agreement matrix heatmap; classify agreement strength |
| Weighted kappa | ordinal categories 1–5; weighted kappa with quadratic weights; compare to unweighted kappa; agreement matrix |
| Per-category analysis | compute per-category kappa for each of the 4 categories; identify which category has worst agreement |
| 3+ raters | 3 raters in columns r1, r2, r3; Fleiss' kappa for multiple raters; overall and per-category kappa |
| Binary classification | binary outcome (yes/no); Cohen's kappa, sensitivity, specificity, and percent agreement; 2×2 agreement table |
| Confidence intervals | compute kappa with 95% CI using both asymptotic formula and bootstrap (1000 samples); compare CI methods |
| Prevalence-adjusted | compute PABAK (prevalence-adjusted bias-adjusted kappa) alongside standard kappa to account for high prevalence imbalance |
| Minimum sample size | how many subjects needed to estimate kappa ≥ 0.70 with 95% CI width ≤ 0.15? compute for κ₀ = 0.70, 2 raters |
Assumptions to Check
- Independence of ratings — each subject should be rated independently by each rater without knowledge of the other rater's assessment; if raters discuss cases before rating, agreement will be artificially inflated and kappa will overestimate reliability
- Marginal homogeneity — standard kappa assumes both raters use the categories at similar frequencies (similar marginal distributions); when one rater systematically uses a category more than the other (marginal heterogeneity), kappa can be paradoxically low even with high raw agreement; PABAK (prevalence-adjusted, bias-adjusted kappa) corrects for this
- Landis & Koch benchmarks are arbitrary — the commonly cited thresholds (0.41–0.60 = moderate, etc.) were proposed without empirical justification; acceptable kappa depends on the application context; a kappa of 0.60 may be excellent for a complex clinical judgment and inadequate for a simple binary classification; always discuss agreement in light of the specific decision stakes
- Weighted kappa choice — for ordinal data, the choice of weighting scheme (linear vs quadratic) changes the kappa value; quadratic weights penalize large disagreements more and equal ICC(3,1); linear weights give equal penalty per ordinal step; choose based on clinical relevance of the error magnitude, not to maximize kappa
Related Tools
Use the Intraclass Correlation Coefficient (ICC) Calculator for continuous measurements where reliability is assessed by agreement in numeric values — Cohen's kappa is for categorical ratings while ICC handles continuous and ordinal scores (with quadratic weighted kappa ≈ ICC(3,1) consistency). Use the Confusion Matrix & Sensitivity Specificity Calculator when one rater is the gold standard (ground truth) and the other is a test — kappa treats both raters symmetrically while the confusion matrix treats one as the reference. Use the Fisher's Exact Test Calculator to test whether the association between two binary raters' classifications is statistically significant — the 2×2 agreement table is a contingency table and Fisher's test provides a p-value for association. Use the Cronbach's Alpha Calculator for scale reliability — when the same construct is measured with multiple parallel items by a single rater, Cronbach's alpha is the appropriate reliability measure rather than kappa.
Frequently Asked Questions
When should I use weighted kappa instead of Cohen's kappa? Use weighted kappa whenever the rating categories are ordinal — that is, they have a natural order where being "one step off" is less severe than being "many steps off". Examples: pain scale (none/mild/moderate/severe), tumor staging (Stage I–IV), Likert agreement (strongly disagree to strongly agree). Unweighted kappa treats all disagreements equally — calling Stage I when the answer is Stage IV is penalized the same as calling Stage I vs Stage II. Weighted kappa with quadratic weights gives partial credit for near-misses and is mathematically equivalent to ICC(3,1) consistency. Use unweighted kappa only when categories are truly nominal with no ordering (e.g., disease type: cardiac/pulmonary/neurological/other — there is no natural ordering between disease types).
Why can kappa be low even when percent agreement is high? This is the kappa paradox (Cicchetti & Feinstein, 1990): when one category has very high prevalence, both raters default to that category most of the time, inflating percent agreement while kappa remains low. Example: if 95% of patients are disease-free, two raters who always say "no disease" achieve 95% raw agreement but κ = 0 (no better than chance). Conversely, when a rare category is almost never used, the off-diagonal cells for that category are near-empty, deflating kappa. The PABAK (prevalence-adjusted, bias-adjusted kappa) accounts for both prevalence imbalance and systematic rater bias; it is defined as 2p_o − 1 and gives 1.0 only when p_o = 1. Report both kappa and percent agreement with category marginals so readers can assess whether the paradox may apply.
What is Fleiss' kappa and when should I use it?Cohen's kappa is designed for exactly 2 raters. Fleiss' kappa generalizes the agreement correction to 3 or more raters, handling the case where each subject is rated by the same k raters. Fleiss' kappa is computed from the proportion of rater pairs who agree for each subject, averaged across subjects and corrected for chance. Note that Fleiss' kappa measures agreement among a fixed set of raters — it is not equivalent to computing all pairwise Cohen's kappas and averaging them (which is a valid but different approach that gives per-pair estimates). If raters are different for different subjects (e.g., each subject is rated by 2 raters chosen from a pool), use a generalized agreement coefficient (Gwet's AC1 or Krippendorff's alpha) instead.