Cronbach's Alpha Calculator
Calculate Cronbach's alpha online from Excel or CSV survey data. Measure internal consistency, item-total correlations, and alpha-if-deleted with AI.
Or try with a sample dataset:
Preview
What Is Cronbach's Alpha?
Cronbach's alpha (α) is the most widely used measure of internal consistency reliability for a multi-item psychometric scale — a questionnaire, survey, or test where multiple items are intended to measure the same underlying construct. Introduced by Lee Cronbach in 1951, it quantifies how closely related the items in a scale are to each other: if all items measure the same latent variable, responses should co-vary and alpha will be high. Alpha ranges from 0 (no internal consistency) to 1 (perfect internal consistency). The formula is α = (k / (k−1)) × (1 − Σσ²ᵢ / σ²ₜ), where k is the number of items, Σσ²ᵢ is the sum of item variances, and σ²ₜ is the variance of total scores.
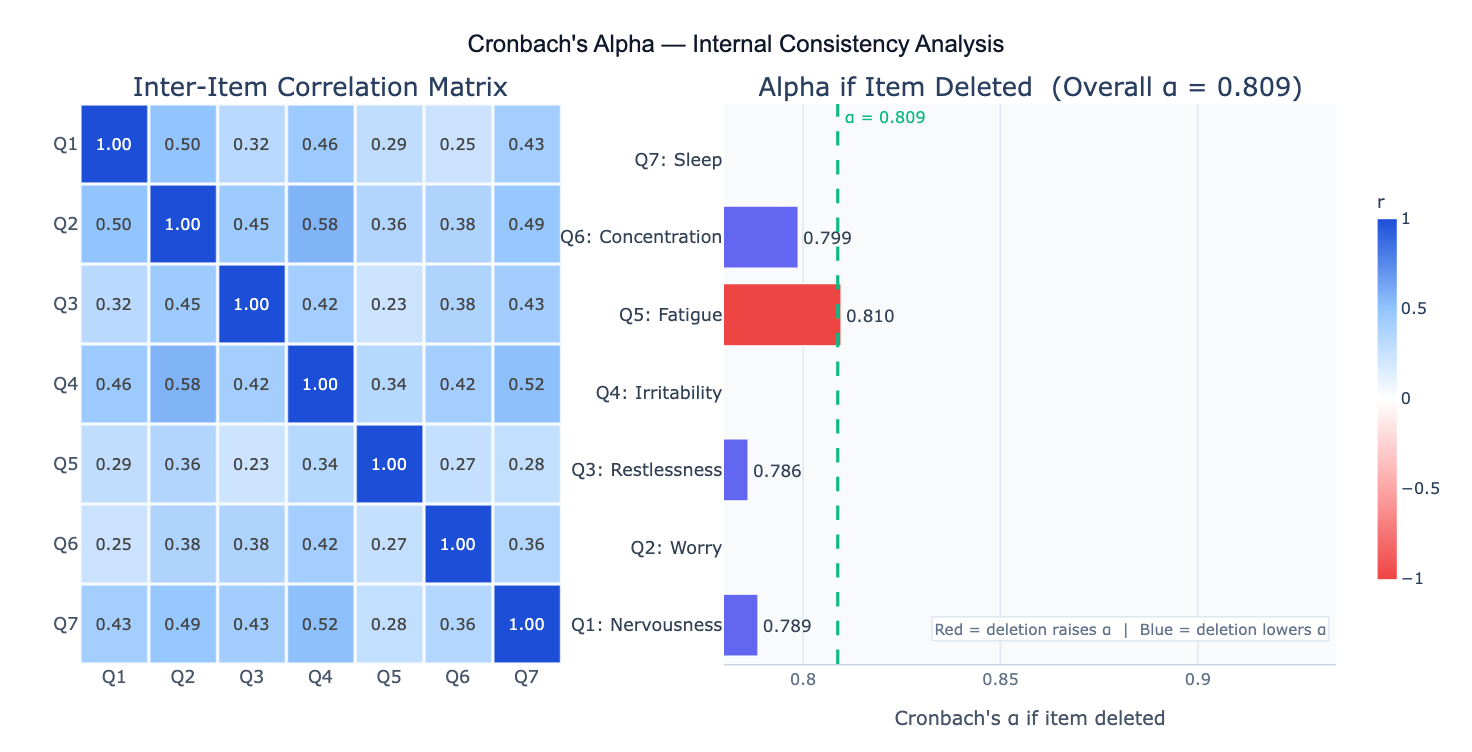
Conventional benchmarks for alpha interpretation: α ≥ 0.90 = excellent (may indicate redundancy); 0.80 ≤ α < 0.90 = good (typical target for established scales); 0.70 ≤ α < 0.80 = acceptable (common in exploratory research); 0.60 ≤ α < 0.70 = questionable; α < 0.60 = poor reliability. These thresholds are guidelines, not absolute rules — a scale measuring a heterogeneous construct (e.g. quality of life) may legitimately have lower alpha than a narrow construct (e.g. a specific phobia). Context and construct breadth matter.
A concrete example: a 9-item depression screening questionnaire (PHQ-9) administered to 250 patients produces α = 0.87, indicating good internal consistency — patients who endorse one depressive symptom tend to endorse others. The alpha-if-item-deleted analysis reveals that item 9 (suicidal ideation), if removed, would raise alpha to 0.89 — not because it is a poor item but because suicidal ideation is a narrower, more specific symptom that correlates less uniformly with the rest of the depression syndrome. This is clinically important information: high alpha alone does not mean every item belongs, and low alpha for a specific item does not mean it should be removed.
How It Works
- Upload your data — provide a CSV or Excel file with one column per scale item (survey questions) and one row per respondent. Items should all be on the same response scale (e.g. Likert 1–5 or 1–7). Reverse-scored items should be recoded before upload, or instruct the AI to recode them.
- Describe the analysis — e.g. "7-item anxiety scale in columns Q1–Q7; compute Cronbach's alpha, corrected item-total correlations, alpha-if-item-deleted; flag items with r < 0.3; heatmap of inter-item correlations"
- Get full results — the AI writes Python code using pandas and pingouin or scipy to compute overall alpha, 95% CI, corrected item-total correlations, alpha-if-deleted for each item, and inter-item correlation matrix, plus bar chart and heatmap visualizations
Required Data Format
| Column | Description | Example |
|---|---|---|
Q1 | Item 1 responses | 1, 2, 3, 4, 5 (Likert scale) |
Q2 | Item 2 responses | 1–5 (same scale as Q1) |
... | Additional items | One column per item |
id | Optional: respondent ID | R001, R002 |
Any column names work — describe them in your prompt. All item columns must be numeric. If some items are reverse-scored (where high means low on the construct), specify which ones and the AI will reverse them before calculating alpha. Rows with missing values are excluded listwise by default.
Interpreting the Results
| Output | What it means |
|---|---|
| Cronbach's α | Overall internal consistency — higher = more homogeneous scale |
| 95% CI on α | Confidence interval; narrow for large samples, wide for small n |
| Corrected item-total correlation | Pearson r between each item and the sum of remaining items — should be ≥ 0.30 |
| Alpha if item deleted | What α would be if each item were removed — flag items where deletion would raise α |
| Inter-item correlation matrix | Pairwise r between all items — should be 0.15–0.50; too high suggests redundancy |
| Mean inter-item correlation | Average of all pairwise item correlations — target 0.20–0.40 for broad constructs |
| Item variance | Variance of each item's responses — very low variance = item has no discriminating power |
| Standardized alpha | Alpha computed from the correlation matrix rather than covariance — useful when items use different response scales |
Example Prompts
| Scenario | What to type |
|---|---|
| Basic reliability check | compute Cronbach's alpha for 10-item scale in columns Q1–Q10; report alpha, item-total correlations, alpha-if-deleted |
| Reverse-scored items | items Q3, Q5, Q8 are reverse-scored (scale 1–7); recode then compute alpha and item-total correlations |
| Flag weak items | Cronbach's alpha; flag items with corrected item-total correlation below 0.3; recommend items to drop |
| Split-half reliability | compute Cronbach's alpha and also split-half reliability (Spearman-Brown corrected); compare both estimates |
| Two subscales | compute alpha separately for subscale A (Q1–Q5) and subscale B (Q6–Q10); compare reliability across subscales |
| Inter-rater reliability | compute Cronbach's alpha across 3 raters for 20 items; heatmap of inter-rater correlations |
| Sample size effect | compute alpha with 95% CI; how many participants needed for CI width ≤ 0.10 at this alpha level? |
| Ordinal alpha | items are ordinal (Likert 1–4); compute polychoric correlations and ordinal alpha as alternative to Cronbach's |
Assumptions to Check
- Tau-equivalence — Cronbach's alpha assumes all items measure the construct on the same scale with equal true-score variances (tau-equivalence); if items have substantially different variances, use omega (ω) as a more appropriate reliability estimate; omega is less restrictive and generally preferred in modern psychometrics
- Unidimensionality — alpha is a measure of reliability assuming the scale measures a single latent factor; if items actually cluster into distinct sub-dimensions, alpha will underestimate reliability within each dimension and give misleading results for the overall scale; run a PCA or factor analysis first to verify unidimensionality before interpreting alpha
- Continuous / interval data — Cronbach's alpha is derived for continuous scores; for ordinal Likert items (especially with ≤ 4 categories), polychoric correlations and ordinal alpha are theoretically more appropriate; in practice, alpha on raw Likert scores is robust and widely used when items have 5+ categories
- No reverse-scored items — reverse-scored items (where high values mean low on the construct) must be recoded before computing alpha; an unreversed negative item will artificially deflate alpha; always check item wording direction
- Sample size — reliable alpha estimation requires n ≥ 100–200; with n < 50 the confidence interval on alpha is very wide and the estimate is unstable; the 95% CI should always be reported
Related Tools
Use the PCA — Principal Component Analysis to verify that scale items are unidimensional (load on a single factor) before interpreting Cronbach's alpha — alpha is meaningful only for unidimensional scales. Use the Correlation Matrix Calculator to inspect the full inter-item correlation structure and identify redundant items (r > 0.80) or poorly correlated items (r < 0.15). Use the Factor Analysis approach to compute McDonald's omega (ω) as a less restrictive reliability estimate when tau-equivalence cannot be assumed. Use the Online t-test calculator to compare alpha values between two independent samples (e.g., different cultural groups) using the Fisher z-transformation.
Frequently Asked Questions
What is the difference between Cronbach's alpha and McDonald's omega? Both measure internal consistency reliability, but they make different assumptions. Cronbach's alpha assumes tau-equivalence — that all items contribute equally to the construct (equal factor loadings in a factor model). If this assumption is violated (items have different factor loadings), alpha underestimates true reliability. McDonald's omega (ω) is derived from a factor model and does not require tau-equivalence — it uses the actual factor loadings to weight each item's contribution. Omega is considered the theoretically superior estimate, and modern psychometric guidelines (APA, 2020) recommend reporting omega alongside or instead of alpha. In practice, when factor loadings are approximately equal, alpha ≈ omega. When items vary widely in their factor loadings, omega > alpha.
My alpha is 0.95 — is that too high? Very high alpha (> 0.90–0.95) can indicate item redundancy — multiple items are so similar they essentially measure the same thing and add no new information. Redundant items increase scale length without improving measurement precision. Check the inter-item correlation matrix: pairs with r > 0.80–0.85 are likely redundant. Also examine item content — if two items are nearly identical in wording, one can be removed without meaningfully reducing reliability. The "sweet spot" for established scales is typically α = 0.80–0.90. Exploratory scales in early development may target α = 0.70+. Very high alpha in a short scale (< 5 items) is less concerning than in a long scale (> 15 items).
Should I remove items to increase alpha? Not automatically. The alpha-if-item-deleted output shows what happens to alpha when each item is removed, but this should not be used mechanically. An item whose removal raises alpha may still be essential for content validity — it may cover a facet of the construct that other items do not. Always consider the theoretical importance of an item alongside its psychometric properties. Items to genuinely consider removing are those that both (1) would raise alpha if deleted AND (2) have corrected item-total correlations below 0.20–0.30 AND (3) are not essential for content coverage. Never remove items based solely on the alpha-if-deleted statistic.
How many participants do I need for reliable alpha estimation? A common rule of thumb is n ≥ 10 respondents per item (so a 10-item scale needs n ≥ 100), but simulation studies suggest n ≥ 200 for stable alpha estimates with typical scale properties. The 95% confidence interval width shrinks as n increases: at n = 50, the CI for α = 0.80 spans roughly ±0.10; at n = 200 it narrows to ±0.05; at n = 500 to ±0.03. For high-stakes scale development (clinical instruments, licensure exams), n ≥ 300 is recommended before finalizing the scale. Report the 95% CI alongside alpha so readers can assess precision.